One of the commonly cited criticisms of distributed version control systems is the lack of a central repository which contains the canonical state of the code. In reality creating such a repository is as simple as anointing one of the repositories as canonical. On the other hand, once such a repository is set up, the problem of access control raises it's ugly head.
Subversion + Access Control
Subversion is the de facto open source centralized version control system and it's use of WebDAV allows it to piggy back on all of the authentication and authorization schemes available to web-servers. In practice this often means that users are managed using a htpasswd file. There are a number of tools that allow one to manage htpasswd files ranging from the TracAccountManager to htpasswd itself.
Thus, adding or removing a user can be as simple as adding or removing a line from a single configuration file.
Handing Out Shell Accounts
The simplest way to share write access to DVCS repositories is to give each user a shell account on the machine that hosts the repository. This allows each user to push and pull changes to the repository using ssh. This strategy has the very nice property that it allows one to access and update a tree over the network without actually making the tree public. The same effect can be achieved using Subversion by requiring commit rights to read the repository, but that is not the default configuration.
It may concern some people to be handing out shell accounts simply to allow write access to a repository. One of the alternatives, inspired by the python development practice is to have a single contributor account on the machine and to use ssh authentication in place of a password.
Using ssh authentication allows several contributors to share the same shell account, without being able to easily subvert it. Interestingly, the python.org developers use Subversion.
Other Alternatives
At work, my team has no less than three separate shared file systems. While not particularly feasible for collaboration over the Internet, for a team united behind a firewall, placing the repository on a shared drive is an extremely simple option.
I have moved Entropy and Ecstasy from it's
previous home on blogger to a new custom blogging application written using
django and coltrane the undocumented and unsupported blogging application for django.
The new application provides one key benefit: It allows me to mark up articles
using reStructuredText. I was getting really fed up with the rich text editor (RTE) that blogger uses. I kept finding myself needing to switch into html mode to achieve the effects that I wanted, but when I switched back to using the RTE, it would freak out.
Additionally, using this custom application gives me a great deal more control over the layout of the blog than was possible using blogger. Granted, I lose some of the ready made functionality available to blogger users, but many of the cool things that blogger offers are implemented and just need to be plugged in. For example, I have already started tagging my posts, but I haven't decided how to display the tags just yet.
Finally, (while this may seem like a disadvantage to those who just want to sit down and start publishing) the new tool chain let's me hack the pieces that don't work quite right. I like tools that let me fool around with the internals, so even if the tools are not polished to perfection just yet, with time I will be able to make them fit my work-flow.
I'm thinking of trying out HAppS in an attempt to further my understanding of Haskell. Looking at one of the examples, I noticed that there was a plea for a server that exposed Saxon so that a new JVM wouldn't need to be invoked every time you style a page just to have access to XSLT 2.0.
This starts the server listening on http://localhost:8080/. This servlet embeds the Winstone Servlet Container so once the WAR is built, you can either start it directly:
java -jar dist/saxon-serv.war
or deploy the WAR using whichever servlet container you prefer.
API
The API is very simple, POST a request to the servlet's root (http://localhost:8080/) with the following arguments:
xml:
The xml document to be styled.
xslt:
The xslt stylesheet to be applied.
I've not yet actually used HAppS for anything yet, so other than pretty printing some very basic xml this server has been completely unused. As such the API and the server's functionality will probably evolve as I use it.
The previous post: Lorem Ipsum to Hebrew gets a little side tracked in the technical details. There's a program to evolve text using mutation-selection cycles and a program to chart the results, but it mostly misses the point.
How can mutations (recombining of the genetic code) create any new, improved varieties?
(Recombining English letters will never produce Chinese books.)
This question has two problems. First, it presents a straw man: nobody contends that mutations alone result in the awe inspiring adaptations possessed by the life all around us. The vast majority of mutations are silent-site mutations and have no effect on the phenotype of the resulting creature, because the mutation occurs in a non-coding section and is never expressed. The majority of the rest of mutations are deleterious and give you cancer or Down's syndrome or something equally nasty. Only a tiny fraction of mutations have any beneficial effect on those carrying the mutation.
Mutation alone would never have produced the staggering variety of life that populates the Earth. Mutation combined with selection on the other hand can produce staggering effect on a population. Mutation introduces novel varieties into a population with each generation. While some mutants will be more fit than than their parents most will not be and some will be decidedly less so. The most fit individuals will found the next generation and beneficial mutations will slowly accumulate generation after generation producing the adaptations observed in current populations.
Second, conceptualizing mutation as moving letters around, is a complete underrepresentation of the ways in which our genome's can be mis-copied. There can be deletions, replacements, duplications of single bases or entire sections of DNA. Additionally, it is at the completely wrong level of granularity. Mutation would not occur on the letters themselves but on the bytes representing them. With only 256 bytes to choose from you can represent either Macbeth or the I Ching with ease. Likewise, using only C, G, A and T you can just as easily spell E. Coli and H. Sapiens and you can almost spell Human immunodeficiency virus, but you would be missing the U.
Conclusion
So how can mutation create new and improved variants? When acting alone, mutation would only ever improve an individual through luck. It is after all a random process and would mostly only introduce deleterious changes. When combined with selection on the other hand, together mutation and selection can produce amazing adaptations by allowing beneficial mutations to accumulate over generations.
How can mutations (recombining of the genetic code) create any new, improved varieties?
(Recombining English letters will never produce Chinese books.)
Lorem Ipsum to "ןגכה9'kpx%y'ךbעX]kגkVגגהiEג9*Qעfעt9fכ9עגכf' qFxה%עגה9תגכג9X' k-?%עגכהןגכה9'" in only 118 generations. Sure it's garbled gobbledygook but if you have any familiarity with Hebrew you should be able to spot kaf, ayin and tav among others. In this string there is a total of 33 Hebrew characters ranging from aleph to tav.
evolution.py is the program which produced this particular piece of gibberish. It models evolution by natural selection by successively evolving a population of phrases for two hundred generations. In the case of this particular string, fitness was calculated as a function of the number of Hebrew characters contained by an individual.
Method
Each population starts as a single copy of Lorem Ipsum. It is allowed to reproduce without the influence of any kind of selection until the population reaches 1024 individuals. At which point only the 1024 fittest individuals will be allowed to be part of the next generation.
Generation n + 1 is composed of the daughters of generation. Each individual produces two offspring and dies (binary fusion) each daughter is an inexact copy of their mother: 1 in 10 bases are replaced by a point mutation. Daughters are then decoded from utf-8 to unicode and then encoded back to utf-8, errors are ignored.
The genome of the mother is recycled until a full 128 bytes are copied to the daugther's genome. Once 2 daughter cells are generated for each mother, the 1024 fittest cells are selected to be the mothers for the next generation.
Three different fitness criteria were used in three different evolutions: # Hebrew characters, # Latin Uppercase characters, # Latin Lowercase characters.
Results
In each of the following figures the absolute fitness of an individual (in terms of the # of relevant characters) is shown on the Y axis while the generation is shown on the X axis. The green dots are the most fit individuals of their generation while the blue dots are the least fit.
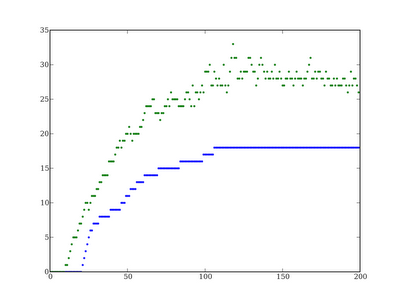
Figure 1: Evolution of Lorem Ipsum when selecting for # Hebrew characters
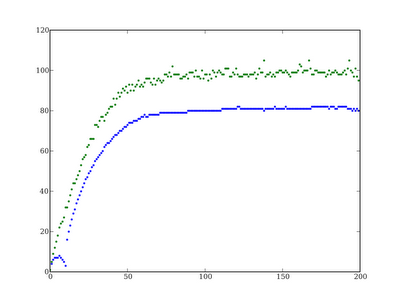
Figure 2: Evolution of Lorem Ipsum when selecting for Uppercase Latin
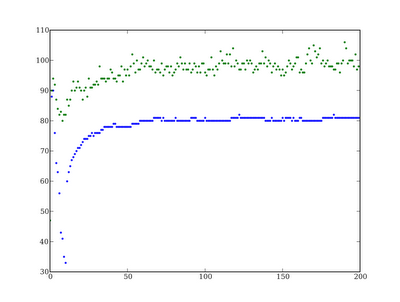
Figure 3: Evolution of Lorem Ipsum when selecting for Lowercase Latin
Discussion
In the three figures there are a couple of important similarities:
Maximum fitness reaches a fitness plateau before it reaches the theoretical maximum in any of the experiments (128 in the case of either Latin experiment or 64 in the case of Hebrew).
Minimum fitness drops off for the first 10 generations in the two Latin experiments.
In two of the three experiments minimum fitness after 100 generations greatly exceeds initial fitness of the population.
Plateau
This is an example of the mutation-selection balance. Essentially, after a certain point the mutation rate is introducing deleterious mutations (replacing characters relevant to fitness with characters that are not) as fast as selection removes them
from the population. Thus the population's fitness reaches a plateau.
The Hebrew experiment was far more susceptible to this effect than either of the Latin experiments because each Hebrew character is represented by two bytes rather than one, the chance of a beneficial mutation is lower and the chance of a deleterious mutation is higher.
Minimum Fitness Dropoff
Lorem Ipsum is a text that is written using Latin characters as such the fitness of the founding individual is greater than zero. Since the population starts with a single individual which divides until it reaches the maximum population of 1024, individuals are not under selection for the first ~10 generations and thus deleterious mutations may accumulate without facing negative selective pressure.
Improved Minimum Fitness Over Time
Lorem Ipsum is a text mostly composed of lowercase Latin characters, as such it is not overly surprising that it shows almost no improvement over time.
On the other hand, the other two experiments show vast improvements in both minimum and maximum fitness over time. In fact the Hebrew experiment starts out with an individual of fitness 0 and results in a population of median fitness ~20 a mere 100 generations later. The Latin Uppercase experiment starts with an individual of fitness ~5 and results in a population with a median fitness of ~85 after 50 generations.
Conclusions
This experiment offers example of several interesting evolutionary effect. We've seen the mutation selection balance in play. Mutations introducing novel variants into the population. The steady increase of fitness over multiple generations. Increase in complexity of the organisms under study (Hebrew characters are represented using two bytes while Latin characters only use one).
Maybe rearranging the letters of the poems of Shakespear can never produce the I Ching, but rearranging the bytes most certainly could.