One of the things that I do enjoy about Ruby is the ability to use blocks to synthesize control structures that may be missing. For instance, I'm a big fan of python's with statement. Through a combination of guerilla patching and blocks, the with statement can easily be added to the ruby language as a library.
Convenience constructors should always call a more general constructor, rather than duplicating the work performed by other constructors. If the general constructor does nothing other then set a few fields, it is tempting to set the fields directly rather than call another constructor; however, doing so invites defects by duplicating code.
Not only is the latter shorter, but should the constructor be modified in the future to establish an invariant, it is much simpler to implement the invariant establishment code in a single location.
Never Do With a Setter That Which can be Accomplished in the Constructor
One of the key benefits of this strategy is that if all parameters needed to initialize the object are available at the time of construction, then fields can be declared final and Immutable objects are simpler than mutable objects.
DRY: Don't Repeat Yourself. The idea that any piece of information in a software system should be specified in one canonical location. This principal applies both in the small: avoiding code duplication and the large: ensuring that configuration information is not duplicated throughout the system.
One of the things that has been irking me while using Ruby on Rails is the difficulty involved in returning a 404 page. For the most part RoR does a good job of Doing-the-Right-ThingTM when encountering an exception, for example, it converts RecordNotFound and RoutingErrors into 404 pages in production mode; however, there are times when I (the programmer) know that a page doesn't exist but RoR has not yet raised an exception. In such cases, it feels truly wrong to simply raise a RecordNotFound exception, as the semantics are questionable and sometimes I'd rather see my 404 page rather than the traceback page, even in development mode. I've found an example of how to coerce Rails to exhibit the desired behaviour; however, it's kind of messy in that it forces every request to be considered public. The following is a far cleaner solution.
Essentially, we override ApplicationController::rescue_action to special case exceptions derived from HttpStatus to set the response status code and render a template. This solution is ideal as it works with both public and local requests and does not interfere with the handling of existing exceptions which already have their own meanings.
The mechanics of how it works are fairly simple: rescue_action is the method that dispatches between rescue_action_in_public and rescue_action_locally, thus by overriding rescue_action rather than either rescue_action_in_public or rescue_action_locally we can define the behaviour of rescue independant of whether or not a request is considered local and thus avoid messing with either local_request? or consider_all_requests_local. Furthermore, by defining our own class of exceptions to invoke the special processing in rescue_action, the applications behaviour is only changed when handling the custom exception, rather than overloading the meaning of existing exceptions.
I recently came across the following bit of strangeness: in Java, an interface cannot have static methods; however, an interface can have public static classes, which themselves can have static methods. Which in effect allows you to put static methods on an interface, like so1:
"Why on earth do you want to put static methods on an interface?" you might ask. Essentially, static methods on an interface would allow the interface designers to provide utilities that do useful things with implementors of the interface without having to create a separate utility class, or worse toss the desired functions into an existing utility class.
I'm somewhat torn on whether this is a particularly good or a particularly bad idea. On the one hand, implementing generic algorithms in terms of interfaces is a truly handy thing to do and providing those implementations close to the interface definition seems to be helpful. Furthermore, creating interface specific utility classes helps to avoid the creation of monstrous Util classes whose cohesion can be summarized as "code other code uses". On the other hand, the designers of the language obviously didn't want actual code injected into interfaces, after all static methods are prohibited on interfaces. As such, I'm undecided. This is either really awesome or really awful.
Collections API: A Case for Utility Classes on Interfaces
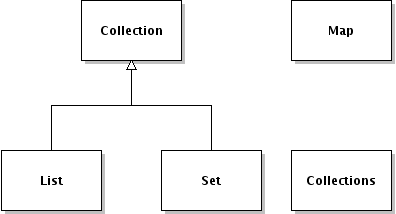
Case-in-point, the collections API2 includes a class named Collections whose sole purpose is to provide interesting and useful methods to implementers of Map, List, Set, Collection and others.
Hierarcy of the classes in the collections API. Shown are the principle interfaces and the Collections utility class.
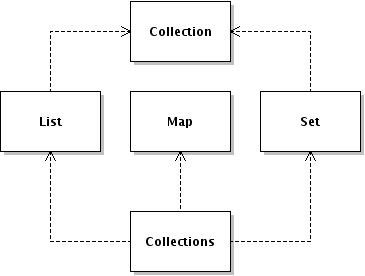
Dependency graph of the collections API. Notice how the Collections class couples together List, Set and Map without any real reason.
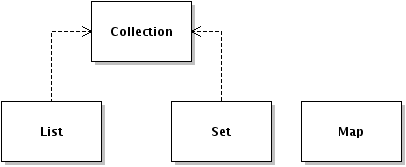
Collections is a large and complicated class with 53 methods (as of Java 6.0) with little cohesion. The class could arguably be decomposed into interface specific utility classes like so:
By providing implementation of the utility methods directly in the interface definition we eliminate the need for the Collections class entierly, and improve the cohesion of the utility methods that are collected together in structure specific utility classes.
We can see that not only does this remove the need for the Collections class, but it also removes the unnecessary dependencies that Collections introduced. Whether that's a compelling enough reason to be a little fast and loose with the definition of interface is up to you.
Notes
For those of you that have made it this far, I'd just like say that the diagrams prepared for this post were created using the Violet UML Editor which is the most pleasant UML editor I've ever used. It is not a CASE tool and it doesn't support sub-states in state diagrams3, but for the most part when you're drawing it Does-The-Right-Thing (TM) and the diagrams look pretty good. So the next time you feel like drawing a class diagram (I can't be the only one who ever feels that way) give it a shot, I think you'll be pleasantly surprised.